Руководство по масштабируемости мобильных приложений
Руководство по масштабируемости мобильных приложений

Ваше приложение набирает популярность: пользователи активно регистрируются, трафик растет, а вместе с ним и доходы. Но в один момент система начинает тормозить, а затем и вовсе перестаёт справляться с нагрузкой. Масштабируемость программного обеспечения определяет, насколько успешно ваша система адаптируется к росту — или терпит неудачу.
Однако масштабирование — это не просто добавление серверов. Без продуманной стратегии вы всё равно столкнетесь с узкими местами.
Например, некоторые компании успешно перешли с монолитной архитектуры на микросервисы, что позволило эффективнее распределять нагрузку. Другие внедрили шардинг баз данных и балансировку нагрузки, чтобы справляться с резким увеличением пользователей.
Как подготовить систему к масштабированию? Что можно использовать для масштабирования?
- Вертикальное масштабирование — увеличение мощности сервера (CPU, RAM, диски).
- Горизонтальное масштабирование — распределение нагрузки между несколькими серверами.
- Оптимизация архитектуры — выбор между монолитом, микросервисами или гибридным решением.
- Инструменты для обработки нагрузки — например, Apache Kafka для потоковой обработки событий и распределения трафика.
Масштабирование — это марафон, а не спринт. Чем раньше вы начнете оптимизировать систему, тем проще будет избежать критических сбоев при росте. Продуманная архитектура и грамотное распределение ресурсов — залог стабильной работы вашего продукта.
Что такое масштабируемость ПО?
Масштабируемость программного обеспечения — это способность системы справляться с растущей рабочей нагрузкой без снижения производительности. Хорошо спроектированная система может поддерживать большее число пользователей и более высокий трафик без сбоев. Масштабируемость обеспечивает адаптивность, надежность и экономичность программного обеспечения по мере роста спроса.
Зачем нужно масштабирование?
Игнорирование масштабируемости при разработке программного обеспечения может привести к серьезным последствиям: простоям системы, финансовым потерям и недовольству пользователей по мере роста нагрузки.
Классический пример — эволюция монолитной архитектуры. Изначально простое приложение, разработанное на популярном фреймворке, со временем становится узким местом из-за увеличивающегося трафика и усложнения функционала. В таких случаях многие компании переходят на микросервисную архитектуру, чтобы распределить нагрузку и ускорить разработку новых функций.
Этот сценарий показывает, как важно заранее закладывать гибкие архитектурные решения, способные адаптироваться к росту. Поздний рефакторинг монолита в распределенную систему часто требует значительных ресурсов и времени.
Оптимальный подход — проектировать систему с учётом будущего масштабирования, выбирая модульную архитектуру, которая позволит наращивать мощности без полного переписывания кода. Это минимизирует риски и обеспечит стабильную работу сервиса при увеличении числа пользователей.
Инструменты масштабируемости
Современные компании активно внедряют инструменты, такие как Kubernetes, для автоматизации развертывания, управления масштабированием ресурсов и повышения производительности систем под нагрузкой. Рассмотрим несколько популярных решений для обеспечения масштабируемости и их применение:
Kubernetes — система оркестрации контейнеров, которая автоматически масштабирует рабочие нагрузки в зависимости от спроса, обеспечивая единообразие развертывания в любых средах.
Docker Swarm — облегченная альтернатива Kubernetes, предназначенная для управления и масштабирования контейнеризированных приложений в кластерах.
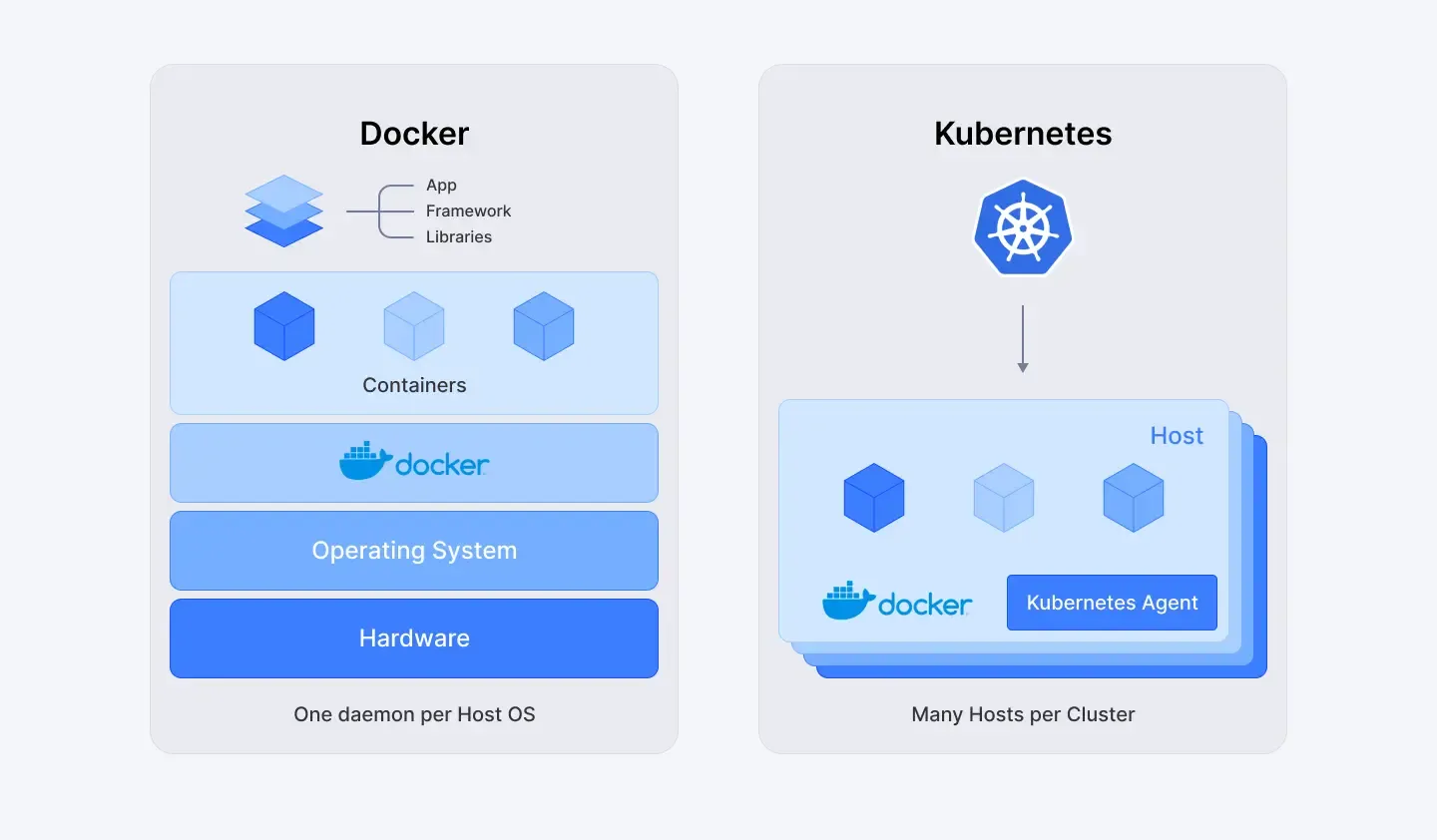
Рис.1 Инструменты масштабируемости: Docker и Kubernetes
AWS Auto Scaling — сервис Amazon, динамически регулирующий вычислительные мощности для поддержания производительности и снижения затрат.
Elastic Load Balancing (ELB) — распределяет входящий трафик между несколькими серверами, повышая отказоустойчивость и доступность приложений.
Prometheus — система мониторинга с открытым исходным кодом, собирающая метрики производительности и оперативно оповещающая о проблемах.
Grafana — инструмент визуализации, интегрируемый с Prometheus для создания дашбордов и контроля масштабируемости инфраструктуры.
Apache Kafka — платформа потоковой обработки событий, обеспечивающая масштабируемую передачу данных между сервисами в реальном времени.
Redis — хранилище данных в оперативной памяти, используемое для кэширования и обмена сообщениями, что снижает нагрузку на базы данных и ускоряет отклик системы.
Hystrix (Netflix) — библиотека для организации устойчивых взаимодействий с внешними сервисами, предотвращающая каскадные сбои.
Terraform — инструмент для управления инфраструктурой как кодом (IaC), позволяющий автоматически и воспроизводимо развертывать ресурсы в облачных провайдерах.
Этот набор инструментов помогает бизнесу эффективно масштабировать инфраструктуру, минимизируя простои и оптимизируя затраты.
Проблемы преждевременного и реактивного масштабирования
Преждевременное масштабирование — это избыточное усложнение инфраструктуры или добавление ресурсов до того, как станет понятен реальный спрос. Оно ведет к перерасходу бюджета, создает ненужную сложность и снижает эффективность системы.
Реактивное масштабирование — это попытка нарастить мощности уже после возникновения проблем с производительностью. Оно чревато простоями, ухудшением пользовательского опыта и неспособностью справиться с внезапным ростом нагрузки.
Успешное масштабирование требует продуманного подхода: пересмотра архитектуры, использования облачных решений и устранения узких мест до того, как они станут критическими.
Стратегии масштабирования
Увеличение количества серверов в растущей системе — это не масштабирование. Ваши масштабируемые программные решения должны эффективно работать при разных уровнях трафика. Без правильной стратегии проблемы с производительностью могут привести к сбою даже в самых перспективных приложениях. Давайте посмотрим, что работает, а что нет.
1. Выявите и устраните узкие места
Чтобы понять, где возникают сбои в работе системы, необходимо постоянно отслеживать ключевые метрики. Без этого можно потратить время на исправление несуществующих проблем, вместо того чтобы решать реальные узкие места. Инструменты вроде Prometheus и Grafana помогают анализировать загрузку процессора, памяти и дисковые операции, а New Relic, Datadog или AppDynamics выявляют задержки в API и неэффективные запросы к базе данных.
Для поддержания стабильной работы распределенных систем требуется постоянный контроль. Например, можно использовать EXPLAIN ANALYZE для выявления медленных SQL-запросов:
EXPLAIN ANALYZE
SELECT * FROM reservations WHERE client_id = 456;
Если поле `client_id` не проиндексировано, запрос приведёт к полному сканированию таблицы, что серьезно замедлит работу. Использование `SELECT *` также увеличивает нагрузку, извлекая ненужные данные. Дополнительные факторы, такие как неравномерное распределение данных или устаревшая статистика, могут влиять на оптимизацию запросов. Решение — добавление индексов, выбор только необходимых полей и актуализация статистики.
Пример улучшения:
CREATE INDEX idx_client_id ON reservations(client_id);
Это значительно ускоряет выполнение запросов и снижает нагрузку на базу. Кроме того, можно применить шардирование и репликацию, чтобы распределить операции чтения/записи между несколькими серверами, устранив ещё один критический bottleneck.
Как выявлять и исправлять проблемы:
- Анализировать загрузку CPU, памяти и дисковые операции.
- Контролировать время отклика API и частоту ошибок.
- Проверять эффективность SQL-запросов.
- Трассировать запросы между микросервисами.
В разработке особенно важно оптимизировать API — например, использовать асинхронную обработку, чтобы медленные эндпоинты не блокировали всю систему.
Частая ошибка: Игнорирование фоновых задач и задержек в очередях, которые могут незаметно снижать производительность под нагрузкой.
2. Оптимизируйте перед масштабированием
Улучшайте код до расширения
Больше серверов — больше трудностей, особенно если ваш код не оптимизирован. Наращивание мощностей без устранения узких мест ведёт к лишним затратам и неэффективному использованию ресурсов. Прежде чем вкладываться в масштабируемые решения, стоит доработать базы данных, запросы и систему доставки контента.
Использование кеширования, например, через Redis или Memcached, может значительно снизить нагрузку на базу данных: как говорится: кешируй или проиграешь.
Рис.2 Масштабирование в Redis
Многие сервисы начинают сталкиваться с проблемами масштабируемости, когда их монолитная база данных не справлялась с нагрузкой. После внедрения индексов и оптимизации запросов скорость обработки данных вырастает в разы. Дополнительно можно перенести статику (изображения, скрипты) на CDN, что сократит время загрузки в глобальном масштабе.
Этот подход подтверждает идею: масштабируемые системы строятся на чистом и эффективном коде, а не на бесконечном добавлении серверов.
Опасная ошибка: избыточное кеширование без грамотной системы инвалидации может привести к устаревшим данным, которые сложнее обнаружить, чем падающий сервер.
3. Выберите правильный подход к масштабированию
Масштабирование не бывает универсальным. Компании могут увеличивать мощность существующих ресурсов или расширять систему за счет дополнительных серверов.
|
Критерий |
Вертикальное масштабирование |
Горизонтальное масштабирование |
|
Прирост мощности |
Мгновенный |
Постепенный (распределенный) |
|
Стоимость |
Высокая |
Экономически выгодное |
|
Отказоустойчивость |
Низкая |
Высокая |
|
Сложность |
Проще |
Сложнее |
Многие сервисы сначала наращивают производительность отдельных компонентов, но вскоре сталкиваются с ограничениями. Для исправления ситуации следует переходить на распределение задач между множеством серверов. Автоматизация процессов, включая использование инструментов для управления инфраструктурой через код, позволяет гибко масштабировать облачные решения.
Масштабируемая архитектура
Чтобы подготовиться к росту и масштабируемому программному решению, необходима правильная архитектура. Выбор между монолитами и микросервисами влияет на масштабируемость, производительность и отказоустойчивость программного обеспечения. Ошибетесь и вы столкнетесь с кошмаром перехода от монолита к микросервису.
1. Микросервисы или Монолит: Когда стоит переходить
Выбор между монолитной и микросервисной архитектурой — одно из ключевых решений для масштабируемости программного обеспечения. Монолиты проще в разработке, но сложнее масштабировать. Микросервисы обеспечивают гибкость, но значительно увеличивают сложность системы.
|
Характеристика |
Монолит |
Микросервисы |
|
Простота разработки |
Высокая |
Низкая |
|
Масштабируемость |
Ограниченная |
Высокая |
|
Скорость развертывания |
Медленная |
Быстрая |
|
Отказоустойчивость |
Низкая |
Высокая |
|
Сложность |
Низкая |
Высокая |
Многие проекты начинают с монолитной архитектуры, так как она требует меньше начальных затрат и проще в управлении. Однако при росте нагрузки проявляются типичные проблемы: увеличиваются задержки, замедляются обновления, база данных не справляется с запросами. Любые изменения в коде могут неожиданно повлиять на работу всей системы.
Переход на микросервисы помогает решить эти проблемы, но требует серьезной переработки архитектуры. Некоторые команды сразу проектируют систему как набор микросервисов, используя современные облачные решения для оркестрации и взаимодействия между сервисами. Однако такой подход не всегда оправдан на ранних этапах, когда требования еще не стабилизировались.
Оптимальной стратегией часто оказывается постепенная эволюция: старт с монолита с последующим выделением критических компонентов в отдельные сервисы по мере необходимости. Это позволяет балансировать между простотой разработки и требованиями масштабируемости.
2. Балансировка нагрузки
Эффективное распределение нагрузки способствует масштабируемости программного обеспечения, равномерно распределяя трафик между серверами. Инструменты, такие как Elastic Load Balancer (ELB), Nginx и HAProxy, предотвращают перегрузку, перенаправляя запросы на доступные экземпляры. Даже масштабируемая система может столкнуться с отказами при резком росте трафика, если балансировка не настроена корректно.
Основные методы распределения нагрузки:
- Автоматическая балансировка (ELB) — динамически адаптируется к изменениям трафика, обеспечивая стабильность системы.
- Ограничение запросов (Rate Limiting & Throttling) — защищает от перегрузки, устанавливая лимиты на количество API-запросов.
- Глобальная балансировка — перенаправляет пользователей на ближайшие серверы, уменьшая задержки.
- Стратегии масштабирования баз данных
В процессе роста любого сервиса рано или поздно возникает необходимость в масштабировании базы данных. Однако непродуманные решения могут не только не улучшить производительность, но и усугубить существующие проблемы.
Репликация: баланс между чтением и записью
Одним из первых шагов в оптимизации часто становится внедрение репликации — настройка главного сервера (Master) для обработки запросов на запись и нескольких реплик (Replicas) для чтения. Это позволяет распределить нагрузку, но требует тщательного контроля: задержки синхронизации между узлами могут привести к несогласованности данных.
Шардинг: распределение данных с умом
Для дальнейшего повышения производительности применяют шардинг — горизонтальное разделение данных между несколькими серверами. Однако ошибки на этапе проектирования (например, неудачный выбор ключа распределения) способны вызвать дисбаланс нагрузки. Чтобы избежать проблем, важно:
- Тщательно проанализировать ключ шардирования,
- Внедрить автоматическое управление шардами,
- Оптимизировать маршрутизацию запросов.
Асинхронная обработка событий
Дополнительным инструментом масштабирования может стать событийно-ориентированная архитектура (например, на основе Kafka или аналогичных технологий), которая позволяет эффективно обрабатывать потоки данных в реальном времени.
Масштабирование БД — сложный процесс, требующий глубокого анализа и поэтапного внедрения. Опыт показывает, что импровизация в продакшене — крайне ненадежная стратегия. Гораздо эффективнее заранее прорабатывать архитектуру, учитывая возможные риски.
Тестирование масштабируемости
Неправильное тестирование масштабируемости программного обеспечения до увеличения числа пользователей может привести к катастрофе. Масштабирование программного обеспечения — это не просто добавление дополнительных облачных ресурсов или имитация трафика. Вы можете проводить бесконечные нагрузочные тесты, но без инструментов chaos engineering, таких как Netflix Chaos Monkey, вы сможете доказать производительность только в идеальных условиях. Это не повысит устойчивость к сбоям в работе. Планирование реальной масштабируемости позволяет подготовиться как к большой нагрузке, так и к неожиданному сбою.
1. Тестирование нагрузки: предотвращение сбоев до их возникновения
Многие технологические компании сталкиваются с проблемами масштабируемости, когда система не справляется с реальной нагрузкой. Отсутствие предварительного тестирования часто приводит к перебоям в работе и экстренным исправлениям, что негативно сказывается на пользовательском опыте.
Чтобы избежать таких ситуаций, необходимо заранее проверять, как система поведёт себя под нагрузкой. Для этого используются специализированные инструменты, такие как JMeter, Locust и k6, которые имитируют действия реальных пользователей и помогают выявить слабые места до запуска в продакшен. Например, можно протестировать, как сервис обрабатывает 1000 одновременных запросов к критически важному API:
k6 run --vus 1000 --duration 1m script.js
Эффективная стратегия масштабирования включает:
- Нагрузочное тестирование с имитацией пикового трафика, резких скачков и высокой конкуренции за ресурсы.
- Интеграцию проверки производительности в CI/CD-процесс, чтобы избежать неожиданных проблем перед релизом.
- Постоянный мониторинг ключевых метрик: пропускной способности, задержек и частоты ошибок.
Рекомендация: тестируйте систему не только на стабильную нагрузку, но и на экстремальные сценарии — это поможет выявить узкие места до того, как они повлияют на пользователей.
2. Автомасштабирование и отказоустойчивость: гибкость и стабильность
Ручное управление ресурсами неэффективно и требует значительных затрат. Современные облачные решения позволяют автоматически масштабировать инфраструктуру в зависимости от нагрузки, обеспечивая стабильную работу без постоянного вмешательства.
Например, в Kubernetes можно настроить автоматическое увеличение или уменьшение количества подов (Horizontal Pod Autoscaler) на основе использования CPU или памяти:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: web-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-service
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 75
Этот подход позволяет:
- Оптимизировать затраты на облачные ресурсы, автоматически уменьшая их в периоды низкой нагрузки.
- Обеспечивать отзывчивость сервиса при резком росте числа пользователей.
Однако одного автомасштабирования недостаточно. Система должна уметь восстанавливаться после сбоев. Для этого применяются:
- Circuit Breaker — механизм изоляции неисправных сервисов, предотвращающий каскадные отказы.
- Мониторинг SLO (Service-Level Objectives) — контроль ключевых показателей доступности и производительности в реальном времени.
Важно: без качественного мониторинга даже гибкая инфраструктура может деградировать незаметно. Регулярный анализ метрик помогает выявлять проблемы до того, как они повлияют на работу сервиса.
Ошибки масштабирования
Вы запускаете новый функционал. Сначала всё работает идеально. Но затем приходит всплеск трафика. Запросы накапливаются, время отклика растёт, пользователи сталкиваются с ошибками. Клиенты разочаровываются и уходят. Вы пытаетесь решить проблему добавлением серверов, но дело не в железе — проблема в архитектуре.
Хорошая разработка строится на системах, которые минимизируют риски, избегают единых точек отказа и работают стабильно. Плохая архитектура приводит к проблемам масштабирования, которые тормозят рост.
1. Слишком ранняя оптимизация
Идеальное — враг хорошего. Строить систему на миллионы пользователей, когда их всего 50, — пустая трата времени и денег.
Пример: один из стартапов изначально не задумывался о масштабировании и выбрал простой монолит на Ruby on Rails. Позже, вместо немедленного перехода на сложные распределённые системы, команда сначала оптимизировала API, упростила логику обработки данных и доработала приложение под реальные нагрузки.
Их стратегия масштабирования была постепенной и осмысленной:
- использовали балансировку трафика,
- переходили на горизонтальное масштабирование только там, где это было необходимо,
- отложили избыточное распределение нагрузок, пока в нём не было нужды.
Вывод: не усложняйте раньше времени. Готовьтесь к росту, но не стройте систему для глобальных нагрузок, пока у вас нет глобальной аудитории.
2. Пренебрежение мониторингом
Скрытые проблемы с задержками могут незаметно ухудшать производительность. Без наблюдения за системой критические ошибки остаются незамеченными, пока не приводят к сбоям.
Тот же стартап поначалу не имел системы телеметрии, из-за чего отладка занимала много времени, а узкие места обнаруживались слишком поздно.
Как они улучшили ситуацию:
- внедрили Prometheus и Grafana для отслеживания проблем в реальном времени,
- настроили сбор и анализ логов для контроля среднего времени отклика,
- начали мониторить облачную инфраструктуру, чтобы снизить задержки и улучшить обработку запросов.
3. Попытки масштабироваться только за счёт железа
Резкий рост трафика нагружает все компоненты системы.
Представьте: стартап запускает рекламную кампанию, и число пользователей резко возрастает. Инженеры реагируют апгрейдом серверов — сначала помогает, но вскоре проблемы возвращаются. Оказывается, дело не в мощности, а в неэффективном коде, перегруженной базе данных и архитектуре, которая не справляется с нагрузкой.
Облака позволяют быстро добавлять ресурсы, но если система не оптимизирована, она всё равно будет тормозить.
Пример: одна компания сначала масштабировалась вертикально — просто наращивала серверы, вместо того чтобы переработать архитектуру. В итоге выросли затраты, а проблемы с данными остались.
Масштабирование — это не просто добавление ресурсов, а продуманная архитектура. В L-TECH мы проектируем системы, которые растут вместе с вашим бизнесом, экономя ваши деньги и нервы.
Не тратьте бюджет на временные костыли — давайте строить сразу правильно.







